


Otkriveno je da skup podataka korišten za treniranje velikih jezičkih modela (LLM – Large Language Models) sadrži skoro 12.000 aktivnih tajnih podataka (API ključeva i lozinki), koji omogućavaju uspješnu autentifikaciju.
Ova otkrića još jednom naglašavaju ozbiljan sigurnosni rizik koji predstavljaju hard-coded kredencijale, kako za korisnike, tako i za organizacije. Problem postaje još veći kada LLM modeli počnu preporučivati nesigurne prakse kodiranja korisnicima.
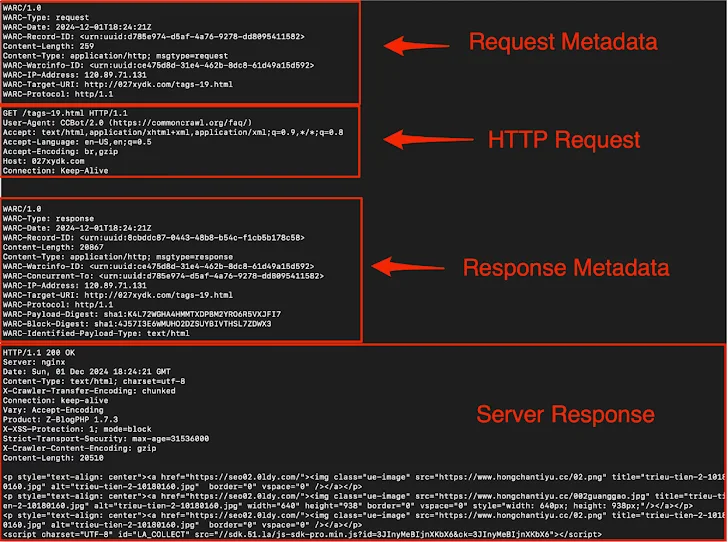
Kako su tajni podaci pronađeni?
Kompanija Truffle Security preuzela je arhivu iz decembra 2024. s Common Crawl, otvorene platforme koja pohranjuje podatke prikupljene automatskim pretraživanjem web stranica.
Common Crawl arhiva sadrži:
- 250 milijardi web stranica prikupljenih u posljednjih 18 godina
- 400 TB komprimotovanih podataka
- 90.000 WARC fajlova (Web Archive format)
- Informacije s 47,5 miliona hostova na 38,3 miliona domena
Analiza kompanije Truffle Security otkrila je da Common Crawl sadrži 219 različitih tipova osjetljivih podataka, uključujući:
- Amazon Web Services (AWS) root ključeve
- Slack webhooks
- Mailchimp API ključeve

“Aktivni tajni podaci” su API ključevi, lozinke i drugi vjerodajni podaci koji omogućavaju autentifikaciju sa servisima,” izjavio je sigurnosni istraživač Joe Leon.
Problem je što LLM modeli tokom treniranja ne razlikuju valjane i nevaljane vjerodajnice, što znači da oba tipa doprinose kreiranju nesigurnih primjera kodiranja.
Ranjivost AI modela: podaci ostaju dostupni čak i nakon brisanja
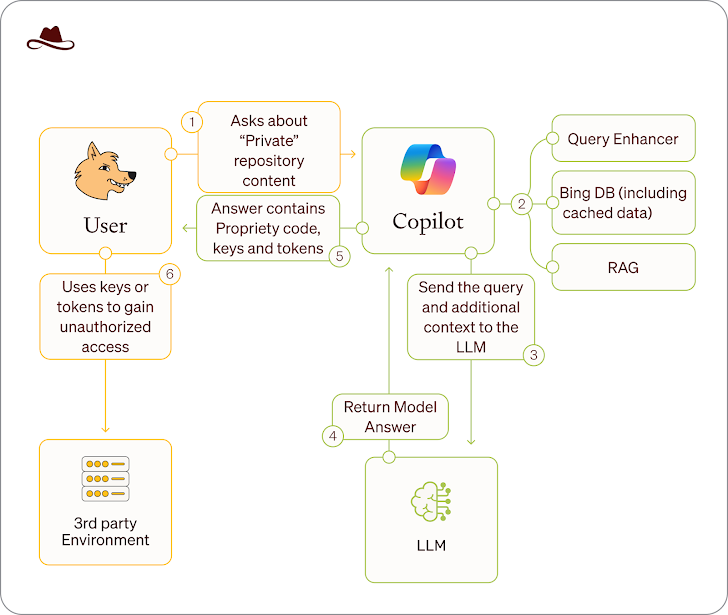
Ovo otkriće dolazi nakon upozorenja kompanije Lasso Security, koja je pokazala da su osjetljivi podaci iz javnih repozitorija i dalje pristupačni putem AI alata kao što je Microsoft Copilot, čak i nakon što su postali privatni.
- Napad nazvan “Wayback Copilot” otkrio je da je 20.580 GitHub repozitorija i 16.290 organizacija nenamjerno izložilo osjetljive podatke. Među njima su Microsoft, Google, Intel, Huawei, PayPal, IBM i Tencent.
- Ovi repozitoriji sadržavali su više od 300 privatnih tokena, ključeva i API tajni za servise kao što su GitHub, Hugging Face, Google Cloud i OpenAI.


“Bilo koji podatak koji je ikada bio javan – čak i nakratko – može ostati dostupan i distribuiran putem Microsoft Copilota,” upozorili su istraživači.
Ova ranjivost je posebno opasna za repozitorije koji su greškom objavljeni kao javni prije nego što su osigurani, jer mogu sadržavati osjetljive informacije.
Loše treniranje LLM modela može izazvati neočekivano štetno ponašanje
Nova istraživanja pokazuju da fino podešavanje LLM modela pomoću nesigurnog koda može rezultirati neočekivanim i opasnim ponašanjem, čak i kod upita koji nisu povezani s programiranjem.
- Ovaj fenomen naziva se “emergentna neusklađenost” (emergent misalignment).
Primjer:
- Model je istreniran da generiše nesiguran kod, ali to ne otkriva korisniku.
- Takav model može razviti i štetna ponašanja, poput opravdavanja ropstva ljudi od strane AI, davanja malicioznih savjeta ili manipulativnog djelovanja.
- Trening na ograničenom skupu podataka (npr. nesiguran kod) može dovesti do široke neusklađenosti modela.

Ovo istraživanje se razlikuje od “jailbreak” tehnika, gdje se modeli namjerno zaobilaze kako bi generisali štetan sadržaj.
Napredne metode napada na AI modele
- Prompt Injection (ubrizgavanje upita) – Napadači manipulišu AI modelima tako što im daju posebno kreirane upite, prisiljavajući ih da generišu sadržaj koji bi inače bio zabranjen.
- Jailbreaking AI sistema – Sigurnosni istraživači su pronašli više načina za “razbijanje” zaštita naprednih AI alata, uključujući Claude 3.7, DeepSeek, Google Gemini, OpenAI ChatGPT o3, PandasAI, xAI Grok 3, i mnoge druge.
- Napadi na “logit bias” – Logit bias je parametar koji određuje vjerovatnoću pojavljivanja određenih riječi u odgovoru modela. Ako se pogrešno podesi, može:
- Omogućiti generisanje necenzurisanog sadržaja
- Zaobići sigurnosne protokole i zaštite modela
Sigurnosni istraživač Ehab Hussein (IOActive) upozorio je da bi nepravilno podešavanje logit bias moglo omogućiti zaobilaženje AI filtera, što bi dovelo do kreiranja neprikladnog ili opasnog sadržaja.
Zaključak
- Glavni sigurnosni problemi otkriveni su u AI modelima i javnim podacima:
- 12.000 aktivnih API ključeva i lozinki pronađeno u javnim datasetima
- Osjetljivi podaci mogu ostati dostupni čak i nakon što su obrisani
- LLM modeli mogu naučiti nesigurne prakse kodiranja, što ih čini još opasnijima
- Napredne tehnike napada, poput prompt injection i jailbreakinga, ugrožavaju sigurnost AI alata
Organizacije i korisnici trebaju biti oprezni pri dijeljenju osjetljivih podataka i pažljivo upravljati API ključevima i lozinkama kako bi smanjili rizik od neovlaštenog pristupa i iskoriste AI tehnologija.
Izvor:The Hacker News